{kind=link}
Imagine communicating clearly in the middle of a deafening construction site or reclaiming a voice lost to medical trauma—all without making a sound. While we’ve long relied on microphones to capture audio, a breakthrough from South Korea suggests we might eventually move past the need for vocalization entirely.
Researchers at the Pohang University of Science and Technology (POSTECH) have developed an AI-powered neckband that translates muscle movements into synthesized speech. This technology doesn’t just enhance how we record audio. it fundamentally changes how we generate it, offering a lifeline to those with speech disorders and a powerful tool for high-noise environments.
The Limitations of Conventional Audio Tech
Traditional microphones, from the built-in mics in laptops to high-end studio gear, share a common vulnerability: they rely on sound waves. Even with modern voice isolation features introduced by companies like Apple and Samsung, audio quality often degrades in the face of extreme background noise and vibrations.
For professionals in high-pressure sectors—such as emergency services, aviation, or maritime operations—this failure isn’t just an inconvenience; it’s a risk. While “legendary” hardware like the Shure SM7B provides professional-grade clarity, the cost is often prohibitive for widespread industrial use, and these mics still require a quiet environment to perform at their peak.
How the AI Neckband Works
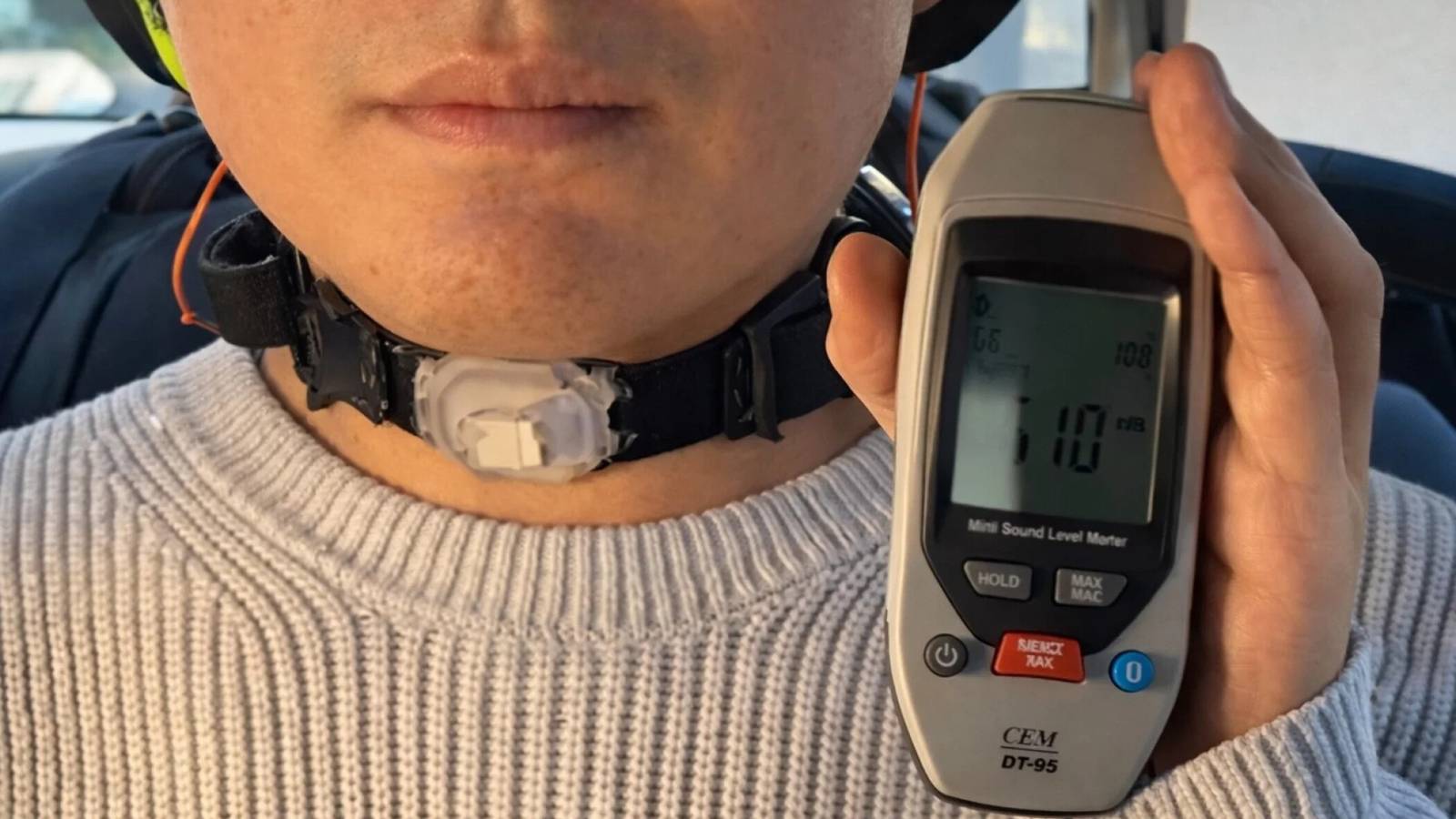
The POSTECH team has bypassed the need for sound waves by focusing on the physical mechanics of speech. The device consists of a silicone neckband equipped with motion sensors and a miniature camera.
Here is the step-by-step process of how the system converts movement to voice:
- Movement Tracking: The sensors and camera monitor the skin and neck muscles as the wearer mouths a word.
- Mapping: The system creates a “roadmap” of how the throat and mouth move to form specific words.
- AI Recognition: An AI model analyzes these patterns to identify the intended word without any actual sound being produced.
- Voice Synthesis: Once identified, the AI synthesizes the word into audio.
To make the voice sound natural, the AI model can be trained on the wearer’s specific vocal characteristics. According to reports from News Atlas, this training requires less than 10 minutes of recordings, allowing the device to mimic the user’s unique intonations and character.
Performance and Real-World Testing
The technology is currently in its early stages, but initial tests show significant promise, particularly regarding noise interference. In environments with white noise reaching 90dB—comparable to a busy construction site—the system maintained a steady signal-to-noise ratio of 33.75 dB. This performance outperforms existing commercial EMG (electromyography) systems under similar conditions.
However, the system still faces hurdles regarding mobility and vocabulary. Current testing has focused on a fixed vocabulary of 26 words using the NATO alphabet (e.g., “Alpha,” “Bravo,” “Charlie”). While the device achieved 85.8% accuracy when the user was stationary, that accuracy dropped by 39.72% when the user walked or moved their head.
Beyond Medical Use: The Future of Silent Communication
While the primary goal is to help laryngectomized patients and those with speech disorders reclaim their voices, the applications extend far beyond the clinic. Researchers publishing in Cyborg and Bionic Systems suggest this tech could replace conventional microphones in settings where audio failure is not an option, including:

- Military and Aviation: Ensuring clear communication in cockpit or combat noise.
- Industrial Facilities: Maintaining safety protocols in loud factories.
- Silent Conversations: Enabling communication in environments where silence is mandatory.
“It is a noteworthy technology because it has a wide range of potential applications, including assisting laryngectomized patients, communicating in noisy industrial environments, and even supporting silent conversations.”
— Professor Sung-Min Park, Lead Researcher at POSTECH
Key Takeaways
| Feature | Detail |
|---|---|
| Core Tech | Silicone neckband with AI, camera, and motion sensors. |
| Training Time | Under 10 minutes of audio recordings. |
| Noise Resistance | Effective at 90dB (construction site levels). |
| Current Accuracy | 85.8% (stationary) for a 26-word vocabulary. |
What’s Next?
We aren’t ready to throw away our microphones just yet. The team at POSTECH is now focused on expanding the device’s vocabulary to support realistic, fluid communication and improving the AI’s ability to filter out “noise” caused by body movements. As these refinements happen, the gap between non-verbal movement and synthesized speech will continue to close, potentially redefining how we interact in the loudest places on Earth.