{kind=link}
NVIDIA Blackwell Ultra: A Leap Forward for Agentic AI and Cost-Effective Inference
NVIDIA’s Blackwell Ultra platform is poised to dramatically reshape the landscape of AI inference, particularly for the rapidly growing fields of agentic AI and coding assistants. New data reveals substantial performance gains and cost reductions compared to previous generations, signaling a new era of efficiency in AI deployment.
The Rise of Agentic AI and the Need for Enhanced Inference
AI agents and coding assistants are driving a significant surge in software-programming-related AI queries. According to OpenRouter’s State of Inference report, these applications accounted for roughly 50% of all AI queries last year, a substantial increase from 11% the previous year. [NVIDIA Blog] This growth necessitates infrastructure capable of handling low latency for real-time responsiveness and large context windows for complex reasoning tasks.
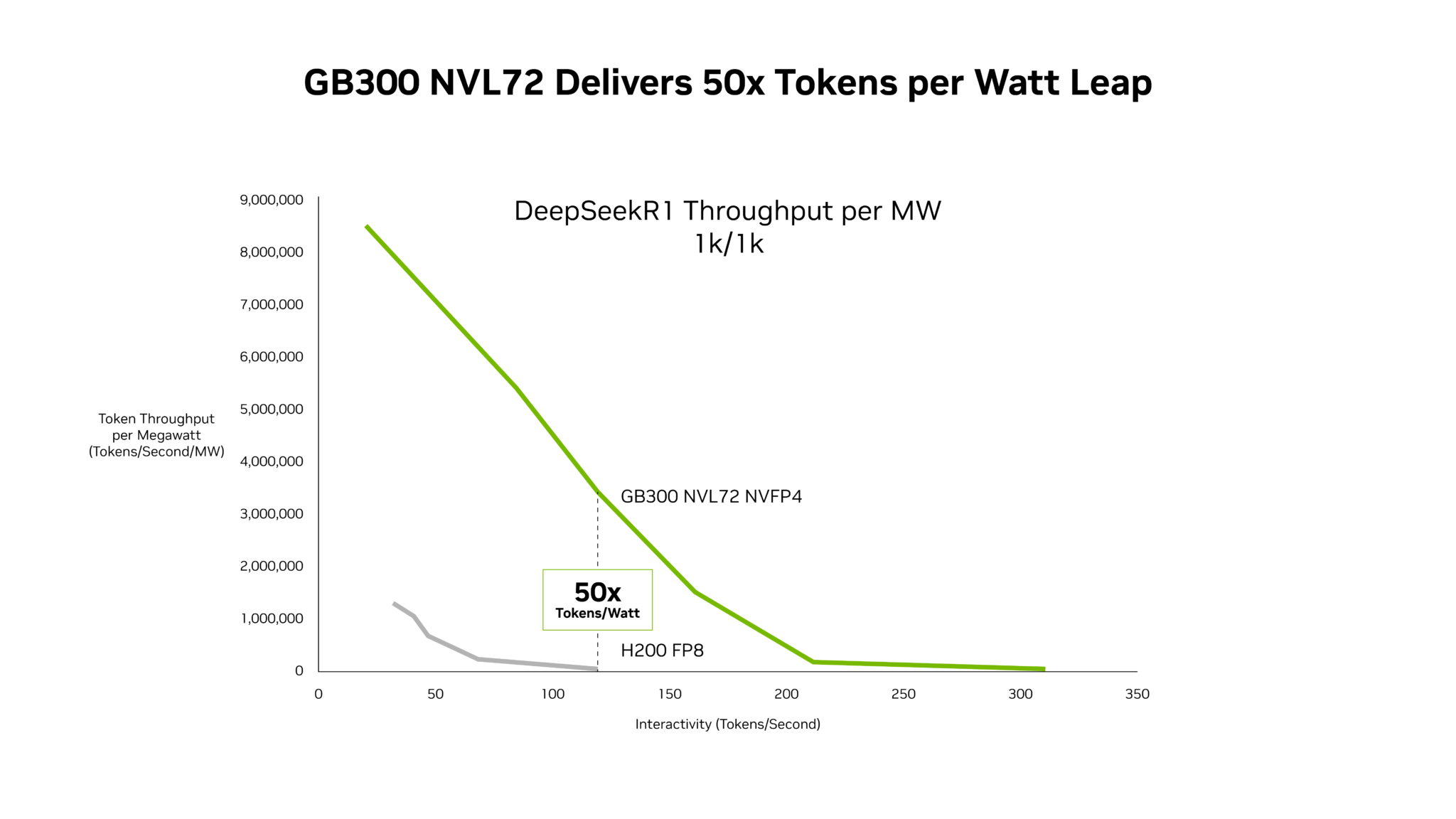
Blackwell Ultra: Performance and Cost Benefits
The NVIDIA Blackwell Ultra platform, coupled with optimized software, delivers breakthrough advancements in both performance and cost-effectiveness. NVIDIA GB300 NVL72 systems achieve up to 50x higher throughput per megawatt, resulting in a 35x lower cost per token compared to the NVIDIA Hopper platform. [Blockchain.News] This improvement is achieved through innovations across chips, system architecture, and software.
Significant Cost Reductions
The GB300 NVL72 systems demonstrate a 35x reduction in cost per token compared to the Hopper platform, particularly at low latency settings crucial for agentic applications. [NVIDIA Blog] Earlier Blackwell systems, like the GB200 NVL72, have already shown a 10x reduction in cost per token for inference providers such as Baseten, DeepInfra, Fireworks AI, and Together AI.
Enhanced Throughput and Efficiency
NVIDIA’s codesign approach, encompassing optimized GPU kernels, NVLink Symmetric Memory for direct GPU-to-GPU access, and programmatic dependent launch to minimize idle time, contributes to the substantial performance gains. [The Neuron] Continuous optimizations from teams working on NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake, and SGLang further boost throughput for mixture-of-experts (MoE) inference.
Long-Context Workloads and NVL72 Advantages
While both GB200 NVL72 and GB300 NVL72 efficiently deliver ultralow latency, the GB300 NVL72 excels in long-context scenarios. For workloads involving 128,000-token inputs and 8,000-token outputs – common in AI coding assistants reasoning across extensive codebases – the GB300 NVL72 delivers up to 1.5x lower cost per token compared to the GB200 NVL72. [NVIDIA Blog] Blackwell Ultra’s 1.5x higher NVFP4 compute performance and 2x faster attention processing enable efficient understanding of entire codebases.
Industry Adoption and Future Outlook
Major cloud providers, including Microsoft, CoreWeave, and Oracle Cloud Infrastructure, are already deploying GB300 NVL72 systems in production environments. [Blockchain.News] CoreWeave highlights the importance of long-context performance and token efficiency as inference moves to the center of AI production, with the GB300 NVL72 directly addressing these challenges.
Looking ahead, NVIDIA’s Rubin platform, combining six new chips into one AI supercomputer, is set to deliver another significant leap in performance. For MoE inference, Rubin is expected to provide up to 10x higher throughput per megawatt compared to Blackwell, translating to one-tenth the cost per million tokens. [NVIDIA Blog]
Keep reading